In spring 2024, my friend and graphic designer contacted me to ask for help with a project. Allegra wanted to update old code and add new features for its website. Naturally I was excited to work on the project, since I’m both an anthropologist and an on-and-off freelance web developer. In my latest research project, I’m combining these two roles for the first time by studying how software developers use generative AI.
With this essay, I’m trying to achieve two things: First, it’s an ethnographic description about the infrastructure of scientific publishing and the kind of care that is needed in order to keep sites like Allegra in operation. Second, it’s an anthropological contribution to the question of how generative AI is changing the culture and political economy of software development.
Infrastructural care with artificial intelligence
I’ve worked with blogs and WordPress, Allegra’s publication software, for a long time. WordPress is popular because it is open source and easy to use, with a vast ecosystem of plugins that extend its functionality. However, as Jessica Barnes (2017) demonstrates, there is often a considerable gap – even a chasm – between the formal promise of a system and the ‘muddy’ infrastructural care that sustains it in practice (cf. Barnes 2017). Infrastructures need continuous maintenance labour in order to persist and, ideally, to remain transparent to those who use them (Star and Ruhleder 1996; Edwards 2009). The complex web of dependencies underlying any WordPress site means that whenever a component is replaced – an operating system version, a software library, a plugin update – there is a non-zero risk of something breaking.
When something does break, or when new functionality is needed, one typically faces a trilemma: speed (cost to client), customisation (features the client wants), and maintainability (compatibility with future versions). It’s easy to pick one, challenging to get two, and often impossible to get all three. In my own work for Allegra and other small scientific publishers, I have typically prioritised speed and let the client choose between customisation and maintainability. Often the end result has been implementing a new functionality and accepting that maintainability would have to be revisited later – a trade-off that, as the episodes below show, shaped both how I worked with the LLMs and what eventually broke.
In 2024, I was commissioned by Allegra to update legacy theme code that was no longer maintainable. I had been chatting with Large Language Models (LLMs) when encountering coding challenges, and my results had mostly been very good – already in late 2024, LLMs were impressive at solving programming issues if you asked the right kinds of questions, even though, at this point, their solutions were all based on chance operations – that is, on probabilistic sampling from their training corpus, with no deterministic feedback from the code being discussed. In this case, however, a solution suggested by OpenAI’s GPT-4o model wasn’t working, and I was getting frustrated. I dumped the whole discussion to Google’s Gemini 1.5 Pro, which replied:
The previous AI’s suggestion was flawed. It seems to be hallucinating a filter hook (uag_render_meta_author) that doesn’t exist in the UAGB_Post class. Unfortunately, overriding the render_meta_author method in this scenario is tricky due to the combination of the singleton pattern and the lack of filter hooks.
The previous AI’s suggestion was flawed. It seems to be hallucinating a filter hook (uag_render_meta_author) that doesn’t exist in the UAGB_Post class. Unfortunately, overriding the render_meta_author method in this scenario is tricky due to the combination of the singleton pattern and the lack of filter hooks.
So, Google’s model was – correctly – blaming the OpenAI model of hallucination. These kinds of interactions were common in the early days of LLM use. Over the roughly two years following ChatGPT’s public release in late 2022, conversational LLMs became a routine part of programming work. With this kind of use, there wasn’t a proper feedback loop, so the divinations of LLMs (see Carlson, Wilenius and Corliss 2023) were mostly educated guesses. The mode of working was not that different from searching web forums for answers. What had changed was the nature of communication with the machine. Instead of the hedging and assessment done personally, I could challenge the reasoning in the chat interface, or even pit different models against each other.
By early 2026, when Allegra contracted me again, this time to fix a bug where contributor profile photos had stopped working, the coding landscape had changed again: agentic coding – often, and loosely, called ‘vibe coding’ – had become the new normal. That meant a new mode of social interaction. Instead of chatting with an LLM, one let it ‘enter the computer’, so to say, and gave it limited (or unlimited!) user rights. You still typed instructions through a chat interface, but instead of just replying with an inferred message, the model viewed files, modified code, tested changes, and performed related tasks either semi-autonomously or fully autonomously.
This sets the programmer – in this case, yours truly – in a wholly different positionality. In terms of Goffman’s (see Levinson 1988) classic participation framework: in both cases of LLM use, the AI is mostly the ‘animator’, the one outputting the code. But in the agentic workflow, instead of the human being the ‘author’ – the selector of code – the human is reduced to being the ‘principal’: the one responsible for the outcome.
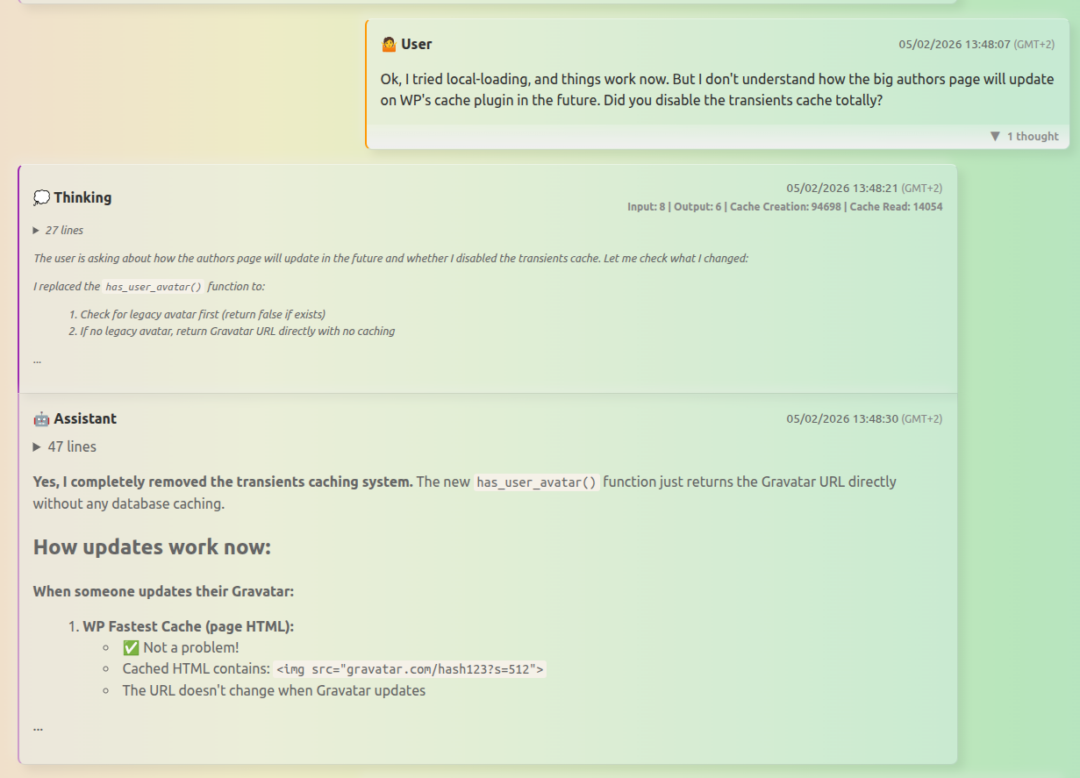
Let me illuminate this change by describing how I worked with the problem. First, I needed to orient the agent to its working environment. I had created a smaller copy of Allegra’s site on my laptop, with most images missing. Early on, the agent thought it had found the problem: the avatar images were missing from the filesystem. This was a false flag – it couldn’t know I was running an incomplete copy – but I should have provided that background information to begin with.
Intensive discussions between myself and the agent were required – bit by bit, we came up with the necessary situational awareness to fix the problem.
During the same scan, however, the agent found the first real clue: my old code assumed the avatar service only sent valid image addresses, with no check for failed or timed-out requests. The agent added these checks, and everything seemed to work on my computer. But a fix on a test server doesn’t always hold on the production server, where environmental factors differ. After a few weeks, the editors told me that avatars for new users still weren’t loading.
What followed was a genuine wild goose chase. It took several missteps – both from me and the coding agent – before we pinpointed the real issue: something in the server infrastructure was causing the avatar service to rate-limit and intermittently block requests. The eventual solution, suggested by the agent, was to let users’ web browsers handle the loading of avatars directly, which made the code much simpler and resolved the problem elegantly.
The key thing is that in the assemblage consisting of myself, the coding agent, my development computer, Allegra’s server, and the content delivery network where avatars were stored, there were multiple ways of representing and executing the code, with different results depending on which combination of technology was in use. A solution that worked flawlessly on my laptop did not function as expected when the constellation of servers was different on the production environment. In order to triangulate this, intensive discussions between myself and the agent were required – bit by bit, we came up with the necessary situational awareness to fix the problem.
Genre machines turning into genres of machines
Ilana Gershon, explaining how LLMs fit into our cultural expectations, dubbed them ‘genre machines’ (Gershon 2023). The early interactions people had with ChatGPT were indeed often requests of genre adjustment, ranging from the ridiculous (‘Turn this pasta recipe into a limerick’) to the prosaic (‘Make this letter more business-like’). Gershon also argued that LLM outputs are non-referential – untethered from any intersubjective semiotic ground (Gershon 2023: 117–118). The models produce text that looks meaningful but is not grounded in the kind of shared social world that gives human communication its referential force. This framing makes sense for LLMs that one chats with, but now that agent models have persistent memory, and powers to use software for ‘sensing’ things deterministically, I am not sure if Gershon’s distinction between human and machine semiosis still holds true.
Another way to conceptualise the chatbot-style interaction is as a form of mechanical divination (Carlson et al. 2023; see also Wilf 2013; Wilf 2023). The models give absolute oracular statements, to be interpreted by humans as they would. The social relationship is clear: a machine divination apparatus on one side, human diviners on the other, with the interpretive burden falling squarely on the humans. This is consistent with Gershon’s semiotic argument – the outputs float free, and it is humans who anchor them in context and meaning. Agentic LLMs disrupt this arrangement. When a model is equipped with tools – the capacity to browse websites, read files, execute code, and modify its environment – it is no longer producing untethered text for human interpretation. Instead, the agent builds feedback loops: it acts, observes the consequences, and adjusts its next steps accordingly. As I described in the previous section, the model navigating a reduced version of the website on my laptop was not producing oracular statements to be divined. It was sensing its environment and reacting to what it found. The clean division between machine divination and human diviner begins to collapse.
The proliferation of such tools will transform genres of work in novel ways, and this is already visible in software development.
So the ‘genre machines’ have evolved into genres of machines, each with their own capabilities: laptop-using software engineers, as I described in the previous section; virtual companions with persistent memories; or LLMs controlling robot bodies, with accompanying concrete physical agency. I am writing this in March 2026, and GitHub, the world’s largest repository of open-source software, has just crowned a new number-one project (measured by stars given by users): OpenClaw, a software suite that turns LLMs into agentic assistants. With software like OpenClaw, if a user can imagine a specific capability for an assistant, they can configure the agent accordingly, or if they don’t know how to do it, they can ask the agent to configure itself.
The proliferation of such tools will transform genres of work in novel ways, and this is already visible in software development. LLM agents are ‘strangely intelligent’ (Chilson and Schwitzgebel 2026) – in some ways far ahead of humans, yet in other domains prone to mistakes that humans would never make. They introduce bugs into software that no human developer would, rendering questions of authorship and responsibility newly urgent.
Colonial code
I will end the essay with two remarks on how to interpret this change in code work. First, the gap that remains after vibe coding is maintenance. Who takes care of the code, and who fixes it when it breaks? For precarious indie sites running on shoestring budgets, regular developer support is unaffordable anyway. Additionally, vibe-coded software is often more idiomatic than the hurried fixes produced by part-time developers like myself, who are often the authors of code in academic indie publishing. This makes them easier to modify or fix by someone – an agent, a human, or a human–agent centaur (see Alves & Cipriano 2023) – when maintenance is next needed. Yet the risk of catastrophic failure sharpens the question: who’s responsible for AI-generated code? Linguistic anthropology offers a way in: participant-role analysis (e.g., Hill and Irvine 1993; Irvine 1996) aims to pinpoint sources of power, structures of hierarchy, and mechanisms of assigning responsibility in social interaction, and the new agent-human constellations of code work demand a similar diagnostic.
The abilities of frontier LLMs are built on data colonialism
For the past year and a half, I have been conducting ethnographic fieldwork among software developers to find out how they think and feel about the changes LLM tools are bringing to their work and organisational structures. The question of responsibility came up several times. However, due to the immaturity of LLM-based solutions, the consensus was that the human user remains responsible for the code. But as more autonomous AI agents start producing software solutions, participant role analysis becomes useful for understanding how agentic coding disaggregates roles that were previously unified in the figure of the software engineer. The principal (whose intentions the code serves), the author (who composes the code), and the animator (who executes the code) are distributed across human users, AI agents, and the infrastructures that sustain them. Tracing this disaggregation – and the resulting gaps in accountability – is a pressing task for software anthropology.
Second, this change in the distribution of participant roles also raises an epistemological question: if code is no longer traceable to a human author, what are the conditions of its production? I call this ‘code from nowhere’ – echoing Haraway’s (1988) critique of the ‘view from nowhere’, the disembodied scientific gaze that claims universal validity while concealing its situatedness. The condition is not entirely new: Adrian Mackenzie (2006: 14) long ago noted that software’s originators tend to be forgotten or cast as ambivalent figures, even as ‘someone or something codes it’. Agentic coding intensifies and formalises this disappearance. While frontier LLMs are presented as a ‘universal solution’ (see Wilenius 2025), they are – like the god trick Haraway identified – thoroughly situated in the political economy of their own production. The code from nowhere relies on training data scraped, often without consent, from open-source repositories and online communities built on networks of mutual aid and voluntary contribution. Put in simple terms: the abilities of frontier LLMs are built on data colonialism (cf. Mejias and Couldry 2024). This accumulated know-how is then repackaged as proprietary AI capability – a ‘magical’ tool that vibe-codes solutions for anyone who asks. The effect is twofold: it obscures the social relations of production behind the code, and it undermines the open-source ecosystems from which the training data was extracted. The growing strain on open-source software communities (see, e.g., Vaughan-Nichols 2026) is not incidental to the rise of agentic coding; it is a direct consequence of it.
We will see a lot more code in the world, thanks to the invention of the transformer architecture that all the current LLMs are based on. It will probably make some of the technical aspects of independent digital publishing easier in the future. But without regulatory intervention, it will also intertwine the infrastructure of publishing with data colonialist processes in new, worrisome ways. I personally remain cautiously optimistic that open-source large language models and software will emerge as the dominant path forward for open science; there are already weak signals (see Longpre et al. 2025) that open-source production models will adapt to the new world of chance operations.
Featured image: screenshot by author.
References
Alves, Pedro and Bruno Pereira Cipriano 2023. The Centaur Programmer — How Kasparov’s Advanced Chess Spans over to the Software Development of the Future. arXiv. https://doi.org/10.48550/arXiv.2304.11172.
Barnes, Jessica 2017. States of Maintenance: Power, Politics, and Egypt’s Irrigation Infrastructure. Environment And Planning D: Society And Space 35 (1): 146–164. https://doi.org/10.1177/0263775816655161.
Carlson, Rebecca, Heikki Wilenius and Jonathan Corliss 2023. On Algorithmic Divination. Platypus 31 October. Retrieved from https://blog.castac.org/2023/10/on-algorithmic-divination
Chilson, Kendra and Eric Schwitzgebel 2026. Artificial Intelligence as Strange Intelligence: Against Linear Models of Intelligence. https://arxiv.org/abs/2602.04986.
Edwards, Paul N., Geoffrey C. Bowker, Steven J. Jackson and Robin Williams 2009. Introduction: An Agenda for Infrastructure Studies. Journal Of The Association For Information Systems 10 (5): 6. Retrieved from https://aisel.aisnet.org/cgi/viewcontent.cgi?article=1508&context=jais
Gershon, Ilana 2023. Bullshit Genres: What to Watch for When Studying the New Actant ChatGPT and Its Siblings. Suomen Antropologi: Journal Of The Finnish Anthropological Society 47 (3): 115–131. Retrieved from https://doi.org/10.30676/jfas.137824
Haraway, Donna 1988. Situated Knowledges: The Science Question in Feminism and the Privilege of Partial Perspective 1. Feminist Studies 14 (3): 575–599. Retrieved from https://api.taylorfrancis.com/content/chapters/edit/download?identifierName=doi&identifierValue=10.4324/9780203427415-33&type=chapterpdf
Hill, Jane H. and Judith T. Irvine 1993. Responsibility and Evidence in Oral Discourse. Cambridge: Cambridge University Press. Retrieved from http://helka.linneanet.fi/cgi-bin/Pwebrecon.cgi?BBID=613481
Irvine, Judith T. 1996. Shadow Conversations: The Indeterminacy of Participant Roles. In Michael Silverstein and Greg Urban (eds). Natural Histories Of Discourse. Chicago: University Of Chicago Press.
Levinson, Stephen C. 1988. Putting Linguistics on a Proper Footing: Explorations in Goffman’s Concepts of Participation. In P. Drew and A. Wootton (eds). Erving Goffman. An Interdisciplinary Appreciation. Oxford: Polity Press.
Longpre, Shayne, Christopher Akiki, Campbell Lund, Atharva Kulkarni, Emily Chen, Irene Solaiman, … Lucie-Aimée Kaffee 2025. Economies of Open Intelligence: Tracing Power & Participation in the Model Ecosystem. https://doi.org/10.48550/arXiv.2512.03073.
Mackenzie, Adrian 2006. Cutting Code: Software and Sociality. New York: Peter Lang.
Mejias, Ulises A. and Nick Couldry 2024. Data Grab: The New Colonialism of Big Tech and How to Fight Back. University of Chicago Press.
Star, Susan Leigh and Karen Ruhleder 1996. Steps Toward an Ecology of Infrastructure: Design and Access for Large Information Spaces. Information Systems Research 7 (1): 111–134.
Vaughan-Nichols, Steven J. 2026. cURL’s Daniel Stenberg: AI Slop Is DDoSing Open Source. https://thenewstack.io/curls-daniel-stenberg-ai-is-ddosing-open-source-and-fixing-its-bugs/. <Accessed 16 March 2026>
Wilenius, Heikki 2025. Kielimallien kulttuurisodat. https://antroblogi.fi/2025/02/kielimallit-ja-kulttuurisodat/. <Accessed 2 February 2026>
Wilf, Eitan 2013. Sociable Robots, Jazz Music, and Divination: Contingency as a Cultural Resource for Negotiating Problems of Intentionality. American Ethnologist 40 (4): 605–618. https://doi.org/10.1111/amet.12041.
Wilf, Eitan 2023. The Inspiration Machine: Computational Creativity in Poetry and Jazz. University of Chicago Press. https://doi.org/10.7208/chicago/9780226828329.001.0001.
Abstract: This essay ethnographically examines the maintenance of small-scale digital publishing infrastructures and the shifting culture of software work under generative AI. Drawing on the author’s dual role as anthropologist and web developer, it traces two moments in WordPress maintenance: early “chatbot” use of large language models (LLMs) for troubleshooting, and later “agentic” or “vibe coding,” in which LLM agents directly inspect, edit, and test code. Through a case of debugging broken profile avatars, the article shows how agentic systems reconfigure human–machine participation roles in coding. In the earlier mode, LLMs functioned as divinatory “genre machines,” producing probabilistic suggestions that humans interpreted and implemented. In the agentic mode, models act within development environments, sense infrastructural constraints, and iteratively adjust their own actions. The human programmer is displaced from author to principal: responsible for outcomes but no longer the primary composer or executor of code. The essay argues that agentic coding produces “code from nowhere,” echoing Haraway’s critique of the disembodied “view from nowhere.” As LLM-generated solutions circulate without clear human authorship, the social and political-economic conditions of their production are obscured. Frontier models are trained on open-source repositories and online communities – often without consent – repackaging collective, volunteer labour as proprietary “magic” that automates new code, even as it strains the very open-source ecosystems it depends on. The author frames this as a form of data colonialism in software development. While autonomous agents may make certain maintenance tasks in independent publishing easier and yield more idiomatic, maintainable code, they deepen questions about responsibility, authorship, and the sustainability of open infrastructures. The article calls for an anthropology of software attentive to infrastructural care, participant-role disaggregation, and the colonial political economy of AI training data, and suggests that open-source models and tools may offer a more just path for scientific publishing in an AI-saturated landscape.



